> ## Documentation Index
> Fetch the complete documentation index at: https://newscatcherinc-docs.mintlify.site/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# Retrieve large datasets
> Retrieve all articles for a query that exceeds the 10,000 article limit using time-chunking across Python, TypeScript, and Java
News API returns up to 10,000 articles per query. For broad queries this limit
is hit constantly — a search for "artificial intelligence" in English returns
10,000 results even when hundreds of thousands of matching articles exist.
This guide walks through the full retrieval workflow in three steps: measure
your dataset volume, choose the right chunk size, then fetch everything. All
three steps include code examples for Python, TypeScript, and Java.
## Before you begin
* An active News API key
* For Python: Python 3.10+ with
[News API Python SDK](/news-api/libraries/python) installed
## Retrieval workflow
Before writing any retrieval logic, use
[`/aggregation_count`](/news-api/api-reference/aggregation-count/get-aggregation-count-by-interval-get)
to understand how many articles your query actually matches and how they're
distributed over time. This tells you which chunk size to use and whether your
query needs narrowing.
```bash cURL theme={null}
curl -X POST "https://v3-api.newscatcherapi.com/api/aggregation_count" \
-H "x-api-token: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"q": "artificial intelligence",
"lang": "en",
"aggregation_by": "day"
}'
```
```python Python theme={null}
from newscatcher import NewscatcherApi
client = NewscatcherApi(api_key="YOUR_API_KEY")
result = client.aggregation.post(
q="artificial intelligence",
lang="en",
aggregation_by="day",
)
print(f"Total articles: {result.total_hits}")
for bucket in result.aggregations[0].aggregation_count:
print(f"{bucket.time_frame[:10]}: {bucket.article_count:,} articles")
```
```typescript TypeScript theme={null}
import { NewscatcherApiClient } from "newscatcher-sdk";
const client = new NewscatcherApiClient({ apiKey: "YOUR_API_KEY" });
const result = await client.aggregation.post({
q: "artificial intelligence",
lang: "en",
aggregationBy: "day",
});
console.log(`Total articles: ${result.totalHits}`);
result.aggregations?.[0].aggregationCount?.forEach((bucket) => {
console.log(`${bucket.timeFrame?.slice(0, 10)}: ${bucket.articleCount}`);
});
```
```java Java theme={null}
import com.newscatcher.api.NewscatcherApiClient;
import com.newscatcher.api.resources.aggregation.requests.PostAggregationRequest;
NewscatcherApiClient client = NewscatcherApiClient.builder()
.apiKey("YOUR_API_KEY")
.build();
var result = client.aggregation().post(
PostAggregationRequest.builder()
.q("artificial intelligence")
.lang("en")
.aggregationBy("day")
.build()
);
System.out.println("Total articles: " + result.getTotalHits());
result.getAggregations().get(0).getAggregationCount().forEach(bucket ->
System.out.println(bucket.getTimeFrame() + ": " + bucket.getArticleCount())
);
```
The response shows total volume and the per-day distribution:
```json theme={null}
{
"status": "ok",
"total_hits": 118562,
"page": 1,
"total_pages": 1186,
"page_size": 100,
"aggregations": [
{
"aggregation_count": [
{ "time_frame": "2026-05-04 00:00:00", "article_count": 18461 },
{ "time_frame": "2026-05-05 00:00:00", "article_count": 20725 },
{ "time_frame": "2026-05-06 00:00:00", "article_count": 20880 },
{ "time_frame": "2026-05-07 00:00:00", "article_count": 20973 },
{ "time_frame": "2026-05-08 00:00:00", "article_count": 15915 },
{ "time_frame": "2026-05-09 00:00:00", "article_count": 6708 },
{ "time_frame": "2026-05-10 00:00:00", "article_count": 5782 },
{ "time_frame": "2026-05-11 00:00:00", "article_count": 9118 }
]
}
]
}
```
118,562 total articles, with 15,000–20,000 per day. Daily chunks would hit the
10K cap every day. You need 6-hour chunks.
Pick a chunk size where each window returns fewer than 10,000 articles. Use the
per-period counts from Step 1:
| Articles per period | Recommended chunk size |
| ------------------------- | ------------------------------------- |
| More than 10,000 per hour | `"1h"` — consider narrowing the query |
| More than 10,000 per day | `"6h"` or `"1h"` |
| 3,000–10,000 per day | `"1d"` |
| 1,000–3,000 per day | `"3d"` |
| 100–1,000 per day | `"7d"` |
| Fewer than 100 per day | `"30d"` |
For the "artificial intelligence" example above: most days have 15,000–20,000
articles, so `"6h"` is the right choice.
With chunk size confirmed, iterate through your date range window by window,
paginating each window fully before moving to the next.
```python Python theme={null}
import time
from newscatcher import NewscatcherApi
from newscatcher.core import ApiError
client = NewscatcherApi(api_key="YOUR_API_KEY")
def get_all_articles(query: str, from_date: str, to_date: str, chunk_hours: int) -> list:
from datetime import datetime, timedelta
articles = []
window_start = datetime.fromisoformat(from_date)
end = datetime.fromisoformat(to_date)
while window_start < end:
window_end = min(window_start + timedelta(hours=chunk_hours), end)
page = 1
total_pages = 1
while page <= total_pages:
try:
response = client.search.post(
q=query,
lang="en",
from_=window_start.isoformat(),
to=window_end.isoformat(),
page=page,
page_size=1000,
)
articles.extend(response.articles)
total_pages = response.total_pages
page += 1
time.sleep(0.5)
except ApiError as e:
print(f"Error on page {page}: {e}")
break
window_start = window_end
return articles
articles = get_all_articles(
"artificial intelligence",
"2026-05-04T00:00:00",
"2026-05-11T00:00:00",
chunk_hours=6,
)
print(f"Retrieved {len(articles)} articles")
```
```typescript TypeScript theme={null}
import { NewscatcherApiClient } from "newscatcher-sdk";
const client = new NewscatcherApiClient({ apiKey: "YOUR_API_KEY" });
async function getAllArticles(
query: string,
from: Date,
to: Date,
chunkHours: number
): Promise {
const articles: object[] = [];
let windowStart = new Date(from);
while (windowStart < to) {
const windowEnd = new Date(
Math.min(windowStart.getTime() + chunkHours * 3600 * 1000, to.getTime())
);
let page = 1;
let totalPages = 1;
while (page <= totalPages) {
const response = await client.search.post({
q: query,
lang: "en",
from: windowStart,
to: windowEnd,
pageSize: 1000,
page,
});
articles.push(...(response.articles ?? []));
totalPages = response.totalPages ?? 1;
page++;
}
windowStart = windowEnd;
}
return articles;
}
const articles = await getAllArticles(
"artificial intelligence",
new Date("2026-05-04T00:00:00"),
new Date("2026-05-11T00:00:00"),
6,
);
console.log(`Retrieved ${articles.length} articles`);
```
```java Java theme={null}
import com.newscatcher.api.NewscatcherApiClient;
import com.newscatcher.api.resources.search.requests.PostSearchRequest;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.List;
NewscatcherApiClient client = NewscatcherApiClient.builder()
.apiKey("YOUR_API_KEY")
.build();
List
## Python SDK: automated retrieval
Python SDK provides `get_all_articles` and `get_all_headlines` — methods that
automate the workflow. They split your date range into chunks, paginate each
chunk, deduplicate results, and return a combined list. You can still measure
volume with `/aggregation_count` to choose a proper `time_chunk_size`, but you
don't need to write the iteration logic.
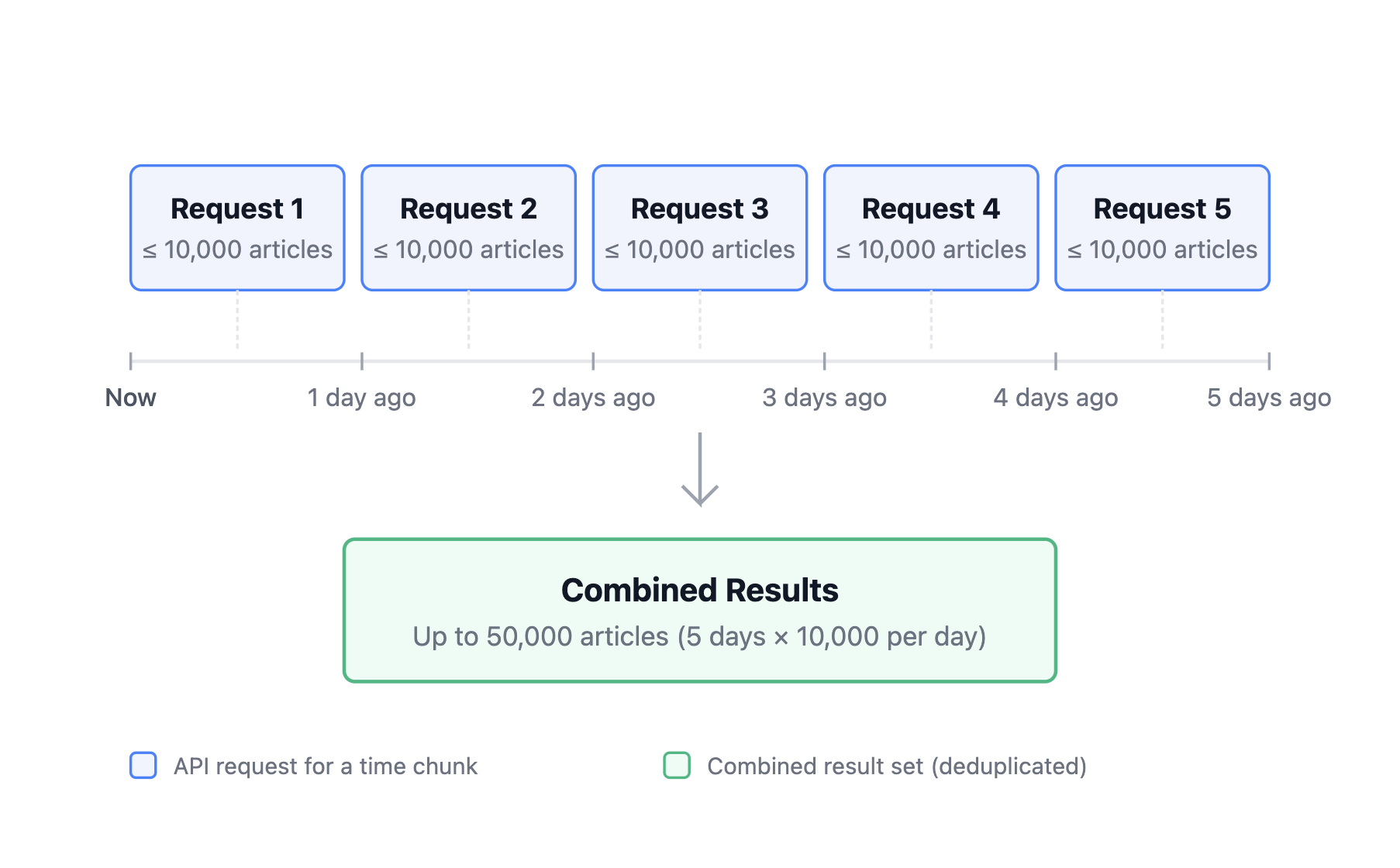
### How time-chunking works
Time-chunking divides your date range into smaller intervals, makes a separate
API call for each period, and combines the results. Each interval can return up
to 10,000 articles.
For example, with `time_chunk_size="1d"` over 5 days, the method makes 5 API
calls — one per day — with automatic pagination, retrieving up to 50,000
articles total.
### get\_all\_articles
Retrieves all articles matching a search query over a date range. Accepts all
standard `/search` endpoint parameters via `**kwargs` — `lang`, `countries`,
`sort_by`, `include_nlp_data`, and so on.
```python Synchronous theme={null}
from newscatcher import NewscatcherApi
client = NewscatcherApi(api_key="YOUR_API_KEY")
articles = client.get_all_articles(
q="artificial intelligence",
lang="en",
from_="7d",
to="now",
time_chunk_size="6h",
max_articles=50000,
show_progress=True,
)
print(f"Retrieved {len(articles)} articles")
```
```python Asynchronous theme={null}
import asyncio
from newscatcher import AsyncNewscatcherApi
async def main():
client = AsyncNewscatcherApi(api_key="YOUR_API_KEY")
articles = await client.get_all_articles(
q="artificial intelligence",
lang="en",
from_="7d",
to="now",
time_chunk_size="6h",
max_articles=50000,
concurrency=3,
show_progress=True,
)
print(f"Retrieved {len(articles)} articles")
asyncio.run(main())
```
### get\_all\_headlines
Retrieves all latest headlines over a time range. Accepts all standard
`/latest_headlines` endpoint parameters via `**kwargs`.
```python Synchronous theme={null}
from newscatcher import NewscatcherApi
client = NewscatcherApi(api_key="YOUR_API_KEY")
headlines = client.get_all_headlines(
when="7d",
time_chunk_size="1d",
max_articles=20000,
show_progress=True,
)
print(f"Retrieved {len(headlines)} headlines")
```
```python Asynchronous theme={null}
import asyncio
from newscatcher import AsyncNewscatcherApi
async def main():
client = AsyncNewscatcherApi(api_key="YOUR_API_KEY")
headlines = await client.get_all_headlines(
when="7d",
time_chunk_size="1d",
max_articles=20000,
concurrency=3,
show_progress=True,
)
print(f"Retrieved {len(headlines)} headlines")
asyncio.run(main())
```
### SDK method parameters
Size of each time window. Accepted values: `"1h"`, `"6h"`, `"1d"`, `"7d"`,
`"1m"`.
Maximum total articles to retrieve across all chunks.
Display a progress bar during retrieval.
Remove duplicate articles from the combined results.
`get_all_articles` only. Validates query syntax locally before making any API
calls. Set to `false` to skip.
`AsyncNewscatcherApi` only. Number of concurrent page requests within each
time chunk.
Both methods accept all other endpoint parameters via `**kwargs` and pass them
to the API. For example, you can filter by language, sort by relevance, or
include NLP data in results from either method — just as you would with direct
API calls to `/search` or `/latest_headlines`.
## Common issues
For async Python, reduce `concurrency`. For manual iteration, add delays
between window requests. If limits are hit consistently, consider narrowing
your query to reduce overall volume.
Your chunk size is still too large. Step down: `"1d"` → `"6h"` → `"1h"`.
For long historical ranges, see
[Working with historical data](/news-api/guides-and-concepts/working-with-historical-data).
Reduce `max_articles` (Python SDK), or write results to disk per window
rather than accumulating everything in memory.
News sources publish continuously. Counts for recent ranges differ between
runs as new articles are indexed. Use a fixed `to` date for reproducible
datasets.
## Best practices
* **Measure before you iterate.** One `/aggregation_count` call tells you the
exact volume and distribution — it takes seconds and prevents wasted API
calls on a wrong chunk size.
* **Set a fixed `to` date for reproducible jobs.** Open-ended `to="now"` means
results change between runs.
* **Use `show_progress=True` during development** (Python SDK). It surfaces
slow chunks and stalls early.
* **Lower `max_articles` if you don't need everything** (Python SDK). The
default is 100,000 — set it to your actual target to avoid unnecessary calls.
* **Store results incrementally for large jobs.** Write to disk per window
rather than accumulating everything in memory.
## See also
* [Aggregation count endpoint](/news-api/api-reference/aggregation-count/get-aggregation-count-by-interval-get)
* [Working with historical data](/news-api/guides-and-concepts/working-with-historical-data)
* [Search endpoint reference](/news-api/api-reference/search/search-articles-post)
* [Rate limits](/news-api/api-reference/rate-limits)
 ### get\_all\_articles
Retrieves all articles matching a search query over a date range. Accepts all
standard `/search` endpoint parameters via `**kwargs` — `lang`, `countries`,
`sort_by`, `include_nlp_data`, and so on.
### get\_all\_articles
Retrieves all articles matching a search query over a date range. Accepts all
standard `/search` endpoint parameters via `**kwargs` — `lang`, `countries`,
`sort_by`, `include_nlp_data`, and so on.