

/search endpoint via the
exclude_duplicates
parameter.
How deduplication works
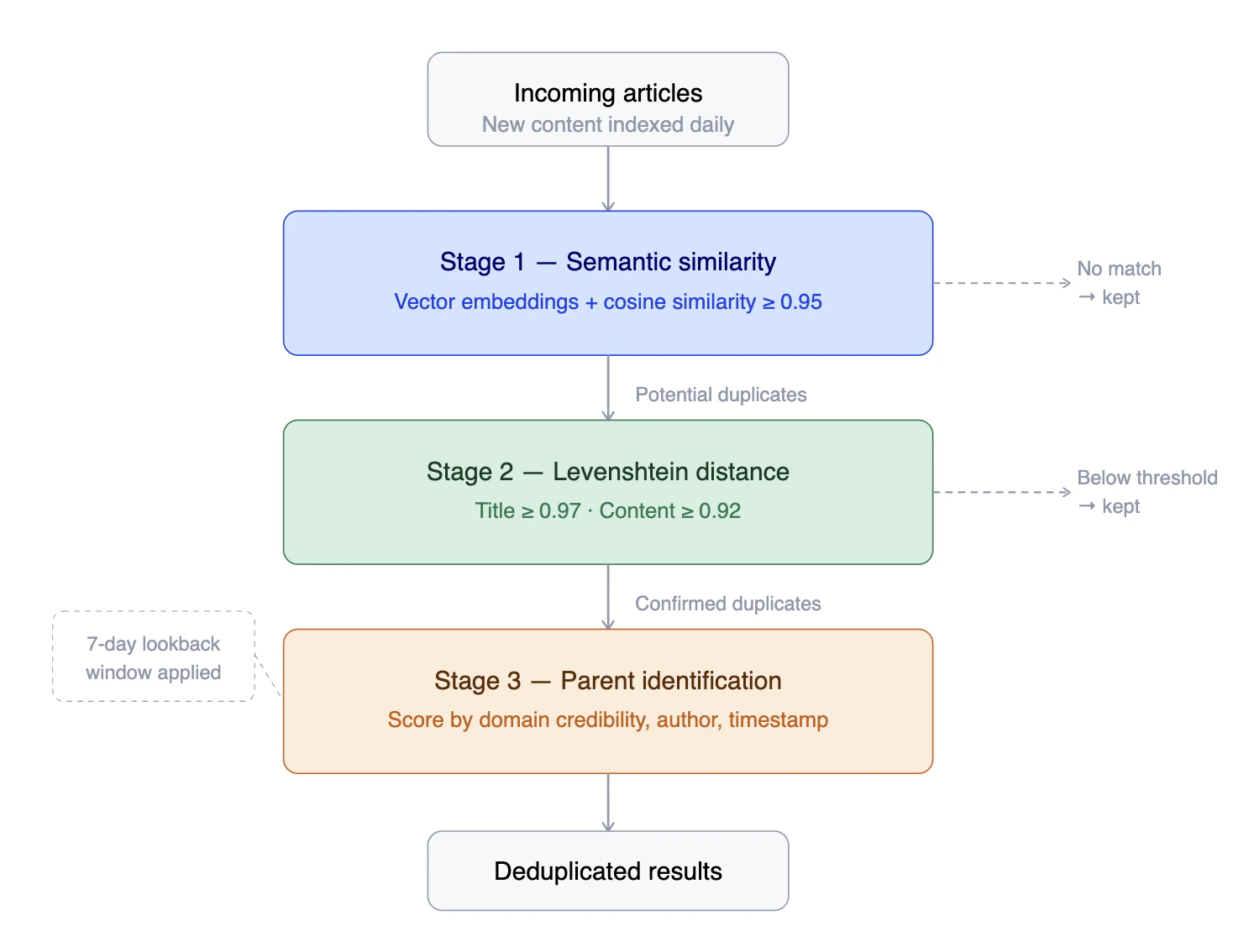
Stage 1 — Semantic similarity
Each article is converted into a vector embedding using the NLP pipeline. News API then computes cosine similarity between article embeddings, flagging pairs that exceed a threshold of 0.95 as potential duplicates. This stage catches articles that cover the same event in different words — rewrites, syndicated content, and articles from different sources reporting on the same facts.Stage 2 — Levenshtein distance
Potential duplicates from Stage 1 are re-evaluated using Levenshtein distance — the minimum number of single-character edits required to transform one text into another. Two thresholds apply:- 0.97 for article titles
- 0.92 for article content
Stage 3 — Parent identification
When a group of duplicates is identified, News API selects the most authoritative article as the “parent” using a scoring algorithm that considers domain credibility, author reputation, and publication timestamp. The parent article is returned in results; duplicates are suppressed. Parent status can change if a newly discovered duplicate scores higher on the credibility algorithm.Lookback window
Each new article is compared against articles indexed in the past seven days. This ensures that duplicates published days after the original — delayed reporting, republished content — are still caught.Enable deduplication in search requests
Setexclude_duplicates to true in a /search request to suppress duplicate
articles:
Response fields
Whenexclude_duplicates is true, each article in the response includes two
additional fields:
| Field | Description |
|---|---|
duplicate_count | Number of duplicate articles suppressed for this result. |
duplicate_articles_group_id | Unique identifier for the duplicate group. Use this to cross-reference groups across requests. |
Deduplication vs clustering
Both features help manage large volumes of articles, but serve different purposes:| Deduplication | Clustering | |
|---|---|---|
| Purpose | Removes near-identical articles | Groups related articles |
| Output | Unique articles only | All articles, organized into groups |
| Similarity threshold | High (near-exact matches) | Lower (topically related) |
| Article count | Reduced | Unchanged |
| Best for | Clean feeds, unique content | Multi-source coverage, trend analysis |